Android Kotlin - Coroutines e Channel
Mediante un esempio di consumatori e produttori si verifica la programmazione di coroutines e la comunicazione fra threads mediante channels
Nello sviluppo di applicazioni Android i tasks, le attività, che richiedono maggior tempo come un interrogazione API di una certa rilevanza, operazioni di decodifica, di download o riproduzione audio etc… non devono essere bloccanti quindi non creare un impatto negativo nel main thread. Questo ovviamente a fronte della creazione di app sempre responsive generando fiducia nell’utente e ottime esperienze di fruizione.
Le coroutines, di recente introduzione nel linguaggio Kotlin (dalla versione 1.3), è soluzione fortemente consigliata per la programmazione asincrona in ambito Android, consente un’ampia semplificazione nella complessità della programmazione asincrona. Co sta per cooperation e routines per funzioni. Uno degli aspetti chiave è che una coroutine è sostanzialmente definibile come un blocco di calcolo, di istruzioni, sospendibile simile ad un thread ma non si tratta di un thread, poichè una coroutine può essere eseguita in un thread, successivamente sospesa e ripresa in un altro thread che è una caratteristica fondamentale nello sviluppo di applicazioni.
Praticamente
Per comprendere nel dettaglio il funzionamento ci si pone il problema dei consumatori e produttori in un buffer prestabilito. Si ammettono dunque
- c numero di consumazioni/consumatori
- p numero di produzioni/produttori
- b grandezza del buffer dove i consumatori possono prelevare e i produttori possono inserire
Nell’esempio allegato (github) (https://github.com/novacoreit/android_kotlin_coroutines_channels) è possibile scaricare il progetto android che si documenta. Si ha sostanzialmente una MainActivity.kt con relativo layout main_activity.xml.
override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) loadView() buttonExecute.setOnClickListener { // launch a lifecycleScope with the executionTask function lifecycleScope.launch(Dispatchers.Default) { executeTask() } } }
Code 1
In, Code 1, nella create dell’activity, dopo una loadView() che si occupa dell'interfaccia, vi è l’esecuzione dell’executeTask() mediante uno scope. Il CoroutineScope definisce il ciclo di vita della couroutine, dunque l’ambito di utilizzo, ci sono tre essenziali scope
- ViewModelScope - definito per la ViewModel quindi il suo ciclo di vita termina alla distruzione della ViewModel.
- LifecycleScope - definito per il ciclo di vita dell’oggetto in cui è chiamata, come nel nostro caso che è abbinata al ciclo di vita della MainActivity, se questa venisse distrutta terminerebbe anche le coroutines dipendenti. Se ad esempio venisse chiamata in un fragment, questa cesserebbe quando quest’ultime viene distrutto.
- GlobalScope - seguono analogamente il ciclo di vita dell’applicazione, dunque finchè questa è viva indipendentemente dall’Activity o dal Fragment “attivo”
La scope nel nostro caso è chiamata con mediante il costruttore launch questo consente il cosiddetto “fire & forget” dunque una volta lanciato non dovrà restituire nulla al chiamante e non bloccherà l’esecuzione corrente. Altro lanciatore async che può bloccare l’esecuzione mediante await(). Inoltre è possibile l’utilizzo di un runBlocking{} dove all’interno è possibile eseguire codice, questo blocca l’esecuzione fino al completamento del “blocco”.
Il Dispatcher, nel nostro esempio Dispatchers.Default, stabilisce quale thread o pool deve utilizzare la coroutine si distinguono per le caratteristiche da svolgere
- Dispatchers.Default - lavoro ad alta intensità di CPU quindi ordinamenti, gestioni di liste di grandi dimensioni, calcoli complessi etc…
- Dispatchers.IO - operazioni di network (chiamate API), lettura e scrittura su file quindi operazioni di Input e Output
- Dispatchers.Main - operazioni relative all’interfaccia grafica
- Dispatchers.Unconfined - non limita la courtine a nessun thread o pool di thread ereditando dal chiamate sono il prima istanza, una successiva sospensione e un resume non garantisce la ripresa nella stessa “tipologia” di thread.
private suspend fun executeTask() { updateUI(true) val bufferSize = editTextBufferSize.text.toString().toInt() val productorsSize = editTextProductors.text.toString().toInt() val consumersSize = editTextConsumers.text.toString().toInt() val channel = Channel(bufferSize) updateUI(0, bufferSize) updateUI("Start from: ${Thread.currentThread().name}") ........ }
Code 2 - executeTask() - estratto creazione channel
In Code 2 vi è la creazione di un channel in modalità buffer con la dimensione desiderata. L’utilizzo del channel è un ottimo metodo di comunicazione fra coroutines poiché supporta un numero indefinito di mittenti e destinatari, quindi nella casistica produttori/consumatori consente di trasferire un valore in maniera univoca mediante le chiamate send e receive. Vi sono modalità di funzionamento dei channel interessanti fra cui
- una capacità di 0 indica la modalità rendezvous che consente il trasferimento unicamente se vi è un incontro tra produttore e consumatore tra send e receive.
- Channel.UNLIMITED - rappresenta una capacità illimitata di immissione
val mainJob = lifecycleScope.launch(Dispatchers.IO) { //var buffer = ArrayList() actualBufferSize = 0 var consumerJobs = ArrayList() var productJobs = ArrayList() var count = 0 repeat(consumersSize) { count++ val job = launch(newSingleThreadContext("ConsumerJob $count")) { consumer(channel, bufferSize) } consumerJobs.add(job) } count = 0 repeat(productorsSize) { count++ val job = launch(newSingleThreadContext("ProductorJob $count")) { productor(channel, bufferSize) } productJobs.add(job) } launch { jobsMonitor(channel, bufferSize, productJobs, consumerJobs) } }
Code 3 - executeTask() - estratto launch dei jobs consumer e productor
In Code 3 si dimostra il lancio, in modalità “fire & forget”, prima dei consumatori e poi dei produttori, solo per scelta dimostrativa, utilizzando come dispatcher un nuovo thread per ogni singolo ConsumerJob e ProductorJob, per poterli identificare.
/* * Productor job, check the possibility of producing until it is possible * */ private suspend fun productor(channel: Channel, bufferSize: Int) { delay((1 until 10).random() * 1000L) channel.send(10) actualBufferSize++ updateUI(actualBufferSize, bufferSize) updateUI("Product from thread: ${Thread.currentThread().name}") } /* * Consumer job, verifies the possibility of consuming the buffer, until it is possible * */ private suspend fun consumer(channel: Channel, bufferSize: Int) { delay((1 until 10).random() * 1000L) val ree = channel.receive() actualBufferSize-- updateUI(actualBufferSize, bufferSize) updateUI("Consumer $ree from thread: ${Thread.currentThread().name}") }
Code 4 - productor() & consumer() - suspended function per produttore e consumatore
In Code 4, le funzioni sospendibili, di produttore e consumatore, con un delay random per simulare richieste e produzioni differite si nota rispettivamente la send e la receive sul channel, queste due “chiamate” comportano la sospensione della coroutine nel caso il buffer sia pieno o quando questo non abbia disponibilità. Il channel consente una gestione estremamente semplificata del buffer e della comunicazione fra thread.
Vi è da notare due cose, nell’executeTask(), vi è un mainJob che include i productJob, consumerJob e un monitorJob che si occupa di verificare se vi siano indisponibilità di consumatori/produttori o viceversa per concludere, cancellare i job pendenti che non possono essere soddisfatti dalla parametrizzazione di start. Il mainJob è “joinato” all’executeTask() per attendere il suo completamento per poi procedere ai logs finali. (riga 88).
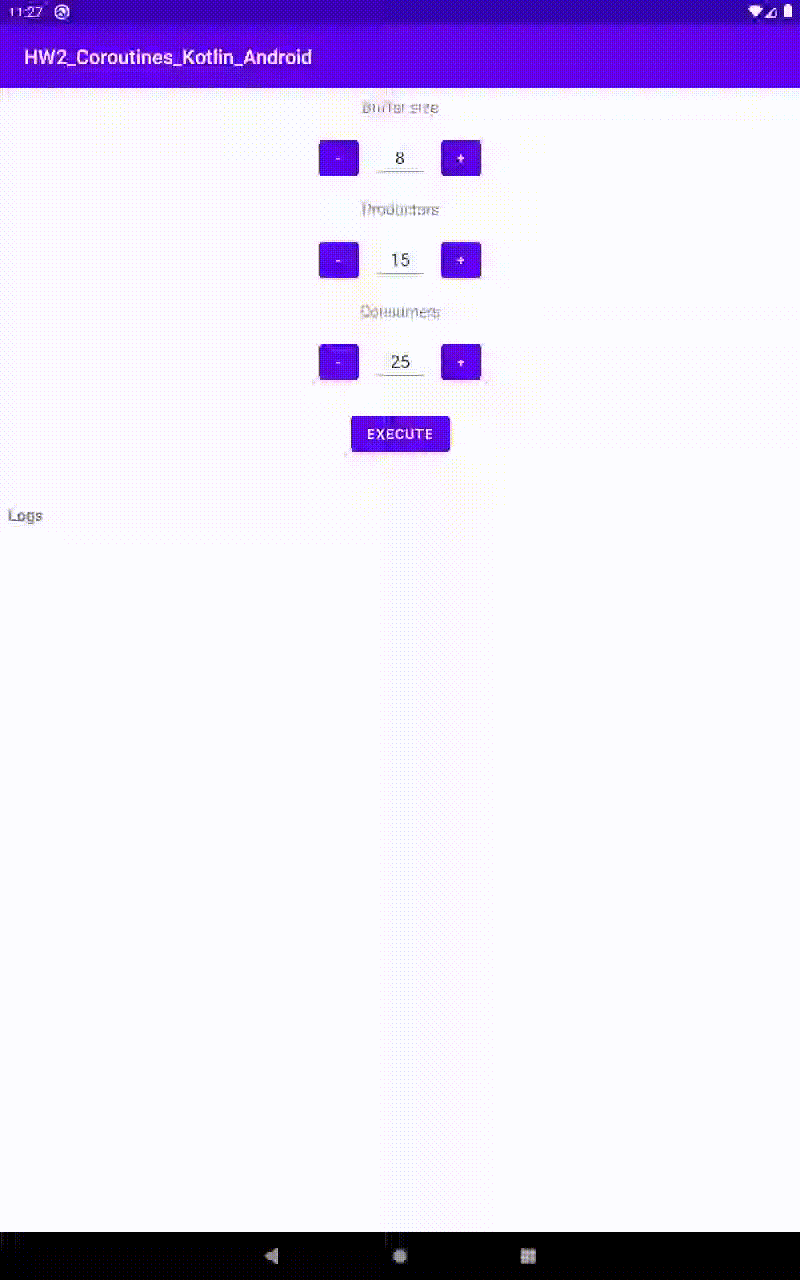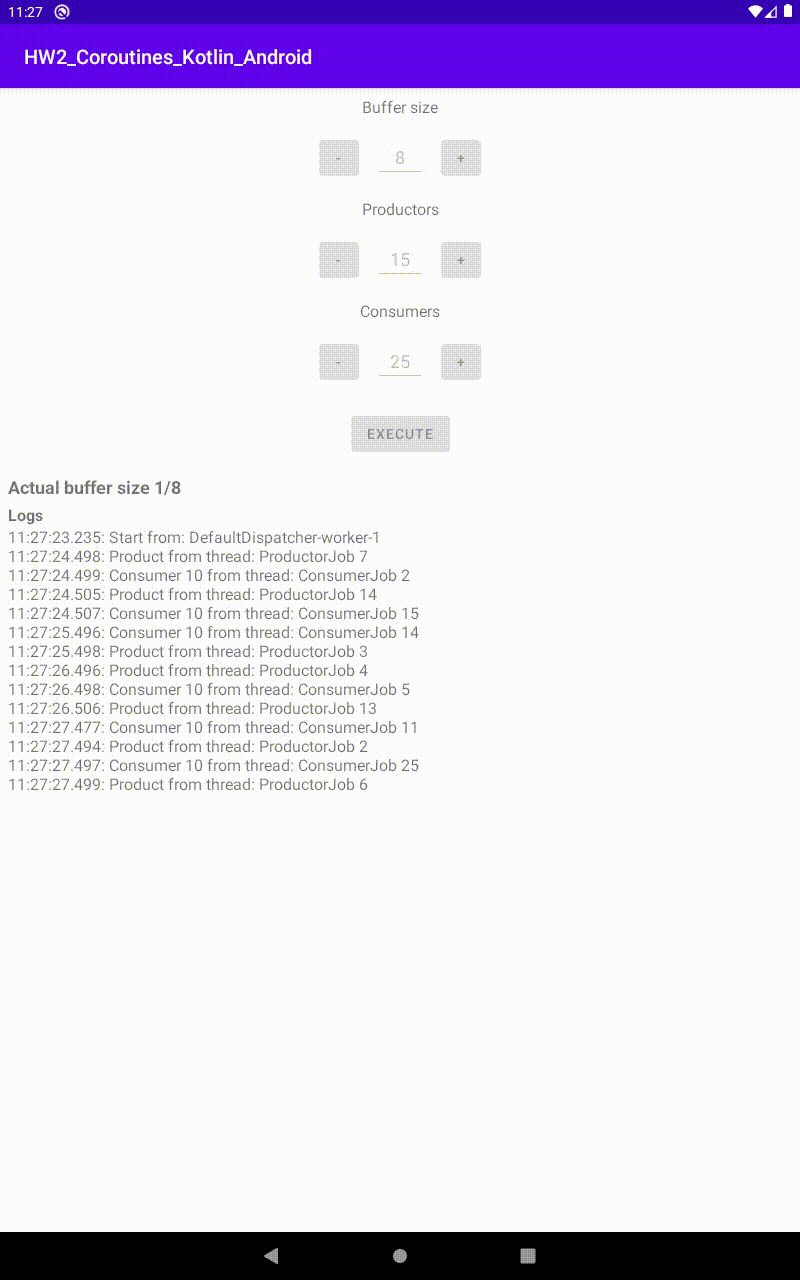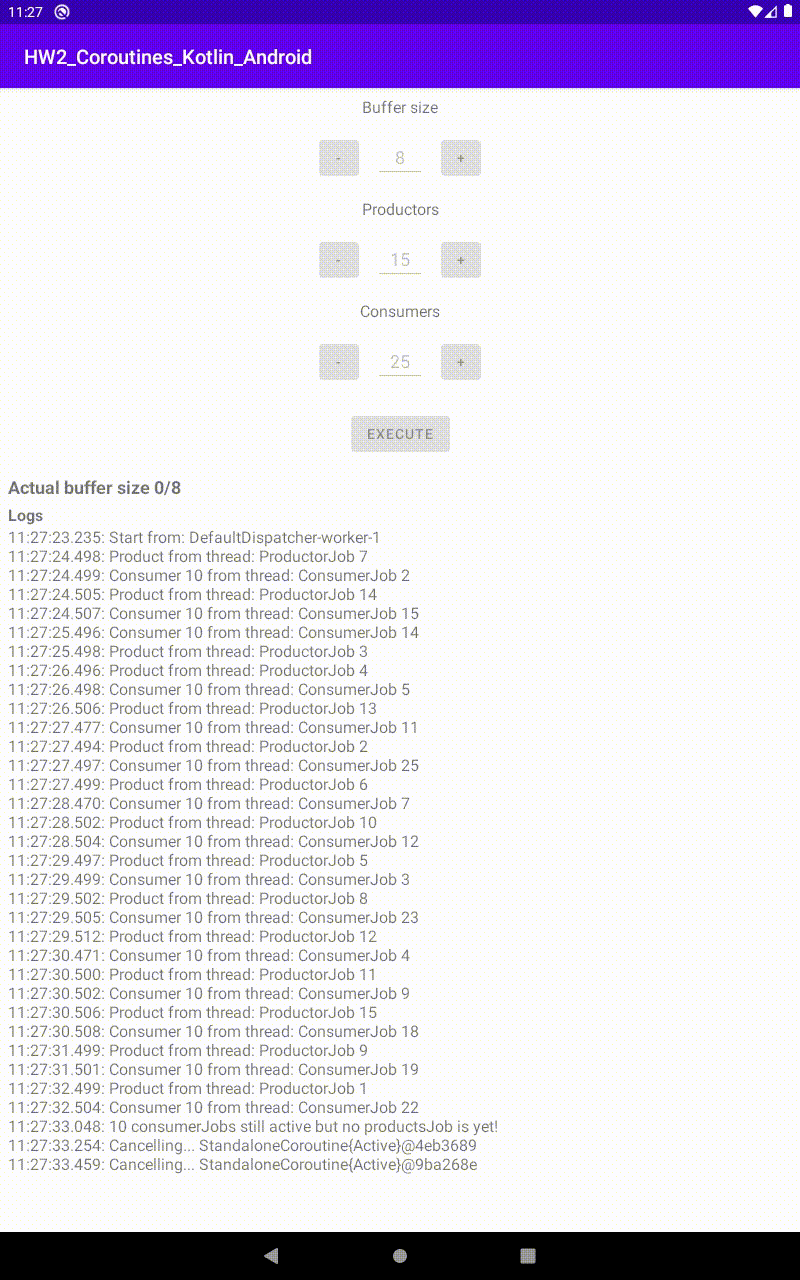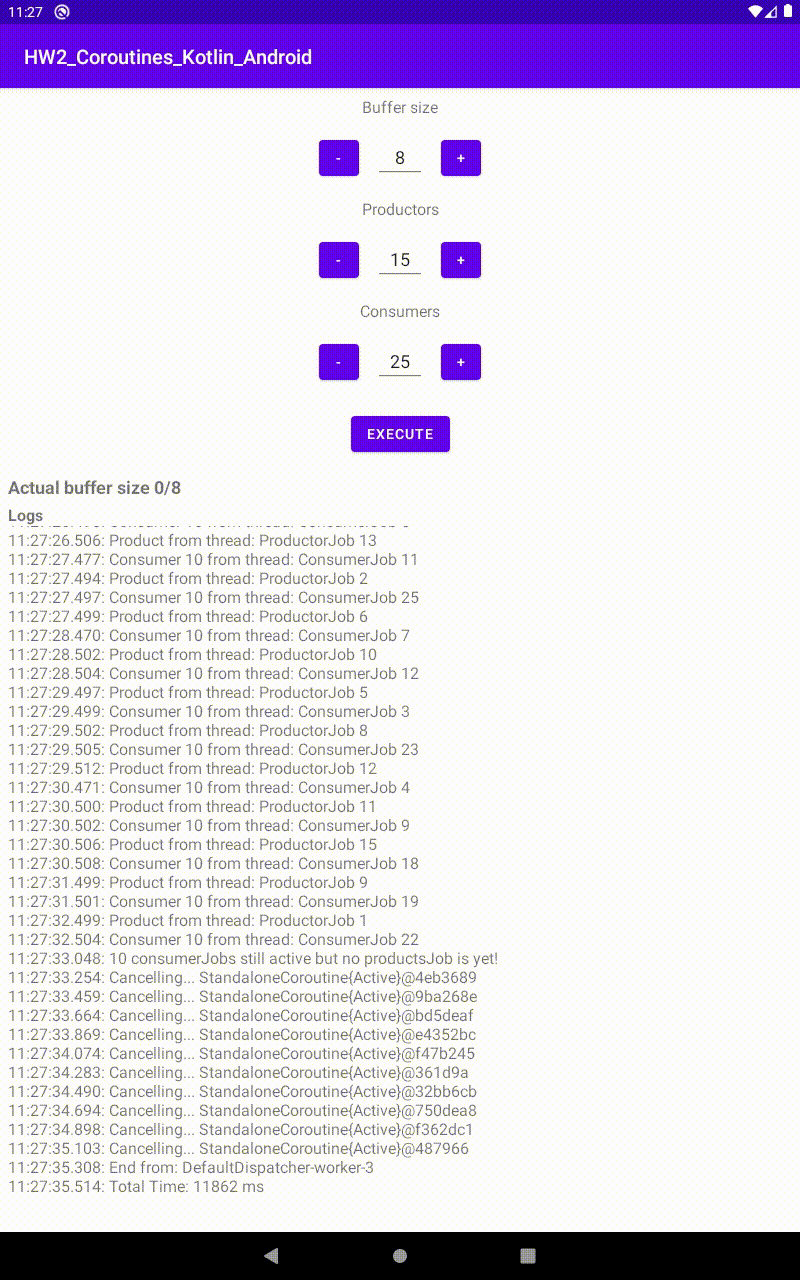 Run con 15 produttori e 25 consumatori, in un buffer di 8 | 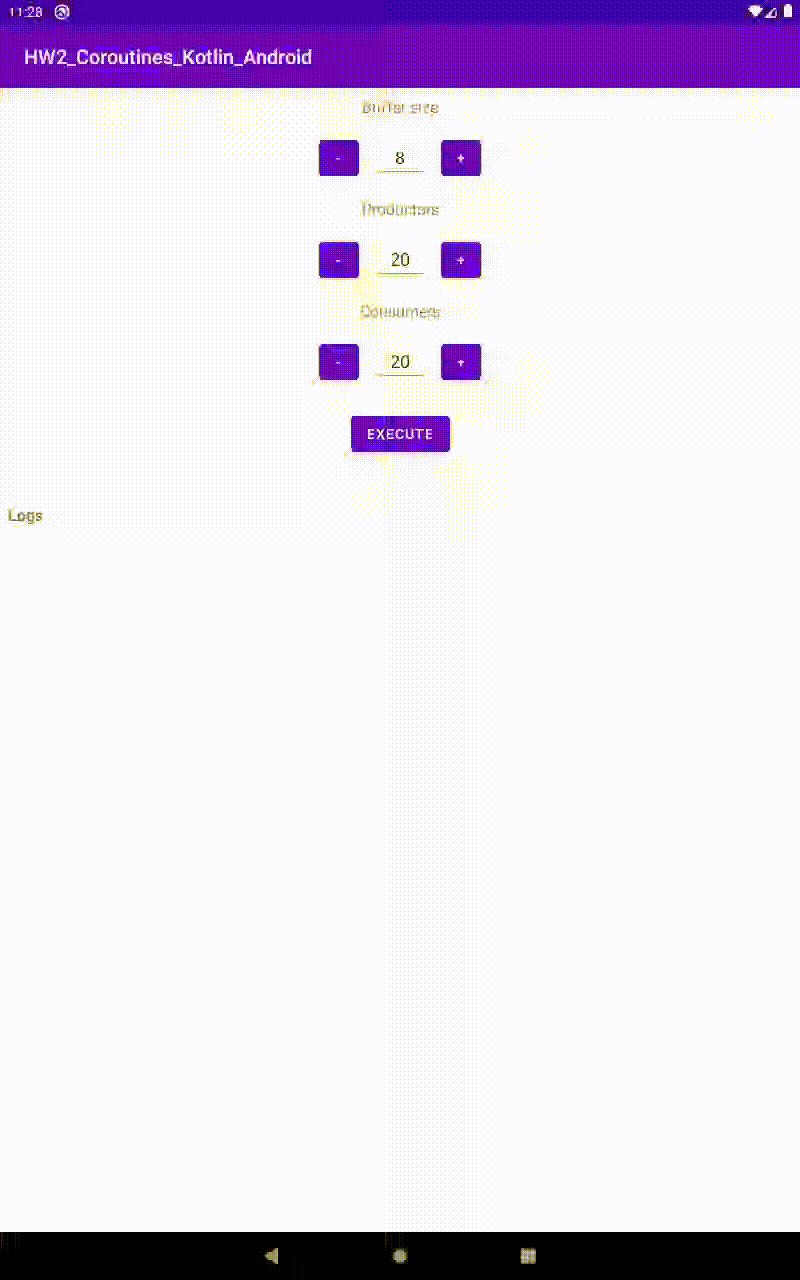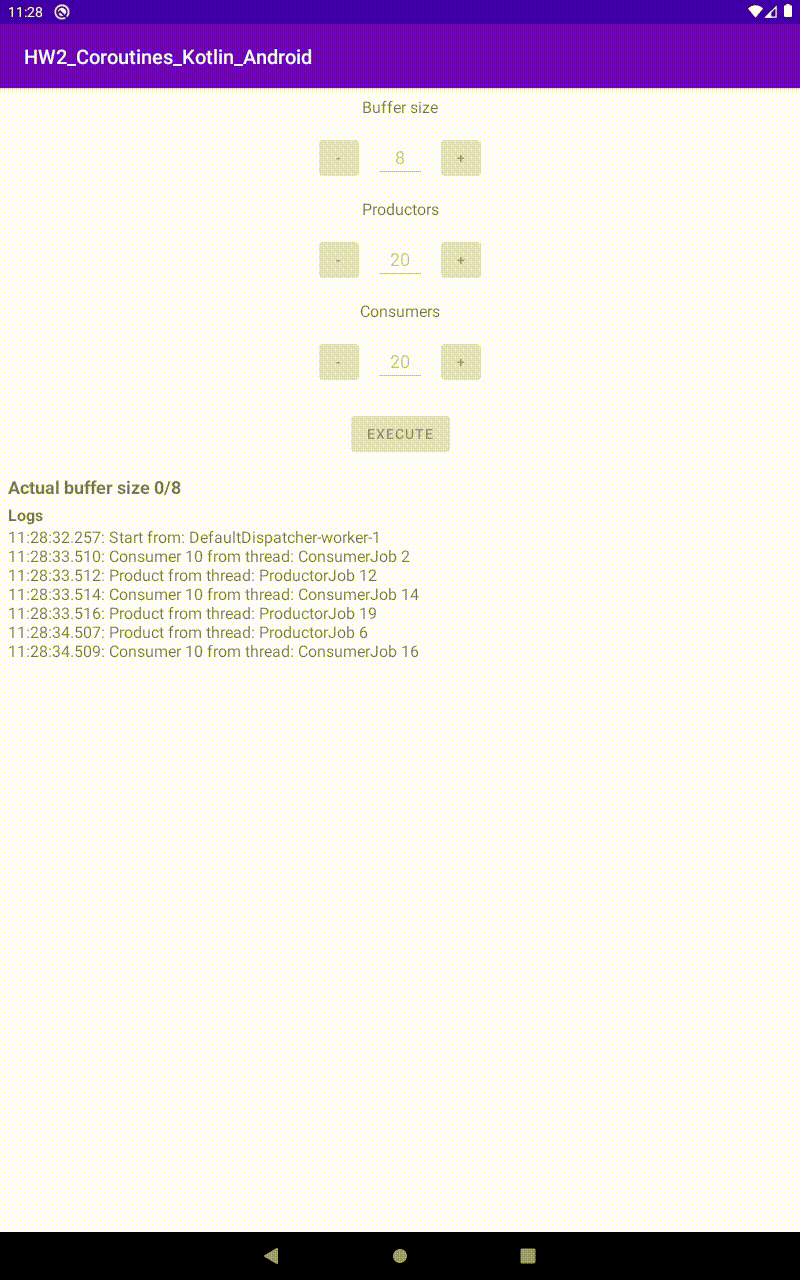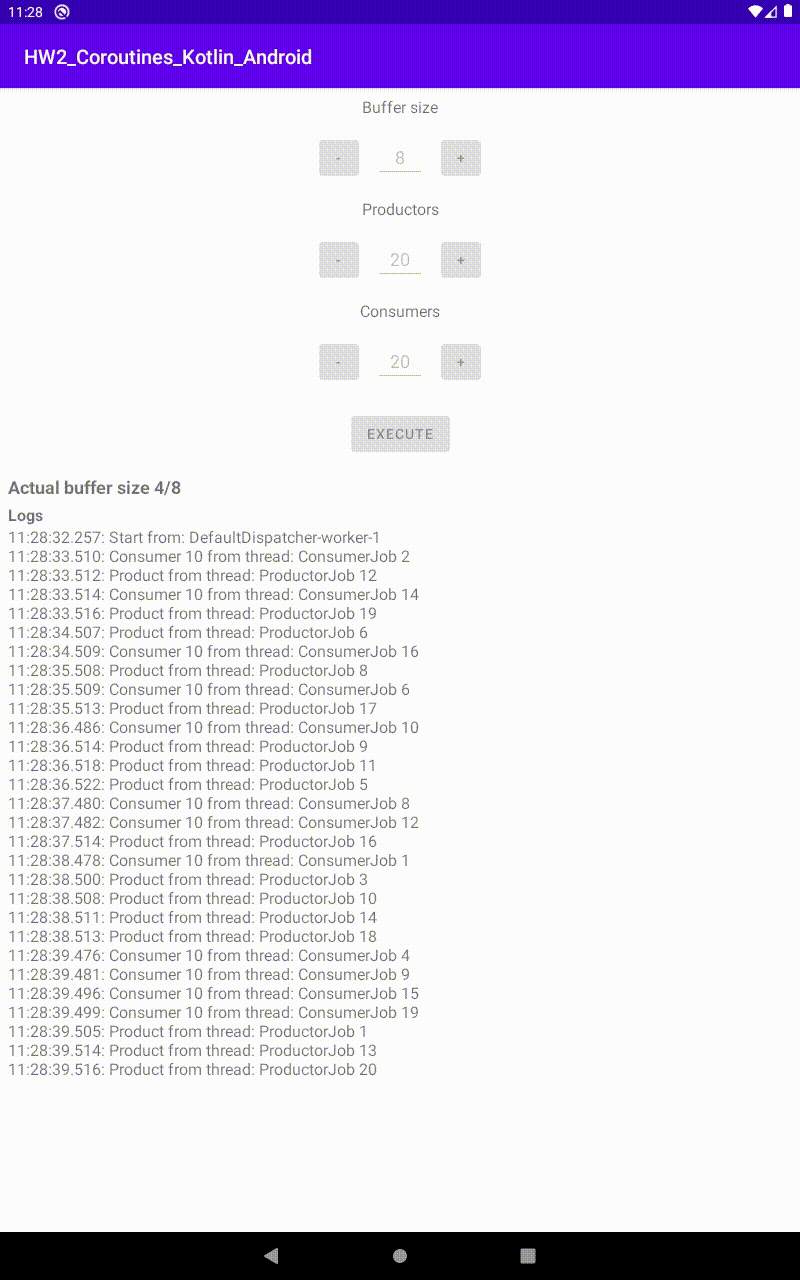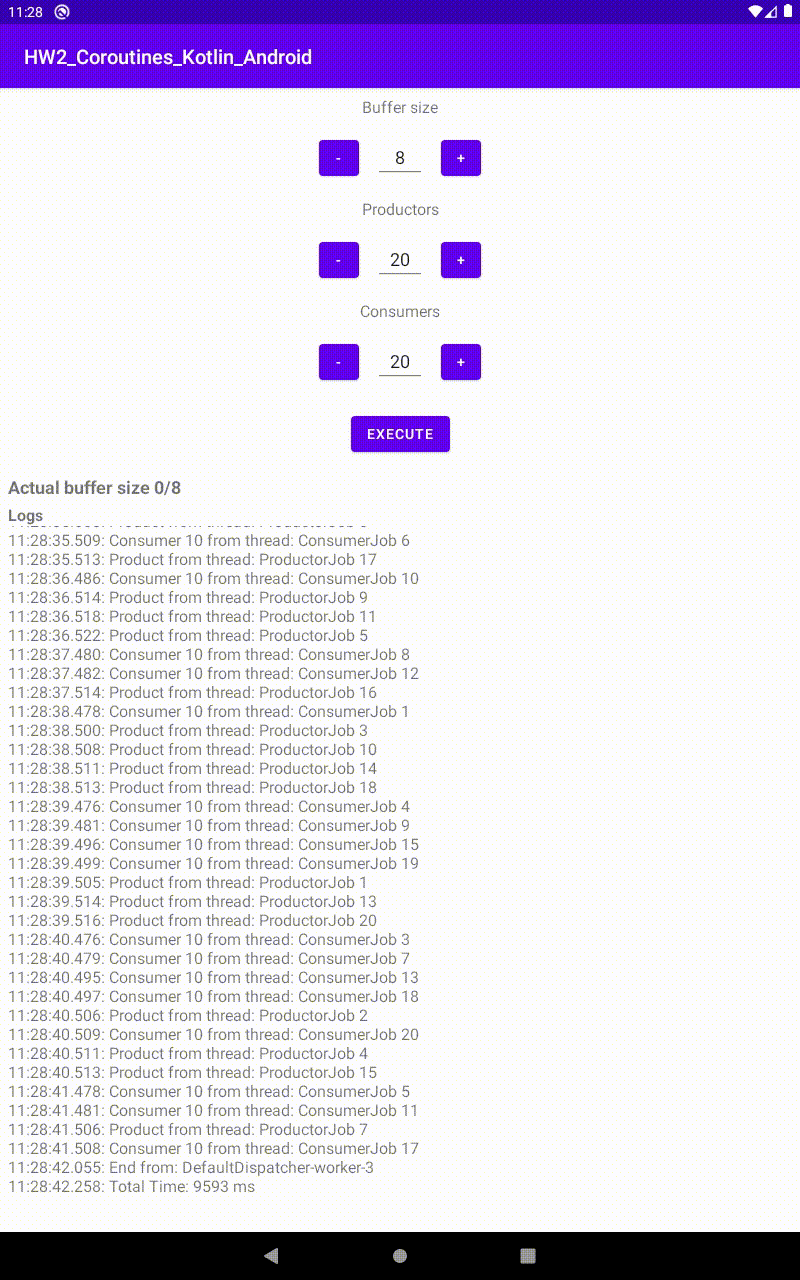 Run con 25 produttori e 20 consumatori, in un buffer di 8 |
Guido Camerlingo
Articoli correlati

MCP (MODEL CONTEXT PROTOCOL) - OpenAI Agent & FastMCP
Model Context Protocol, MCP, OpenAI, Claude Desktop, intelligenza artificiale, API, machine learning, integrazione AI, protocollo aperto, strumenti esterni, FastMCP

Classificazione di testo senza addestramento
La Zero-Shot Classification è una tecnica di classificazione del testo che utilizza modelli pre-addestrati per assegnare etichette a frasi mai viste, basandosi sull'analisi semantica dei vettori di testo.
Amiamo le cose fatte bene.
Conosciamo bene la lingua delle macchine ma, prima di tutto abbiamo un cuore... e potrebbe spezzarsi
al primo bug. Siamo cerebrali nella pianificazione e nell'efficienza quanto romantici e passionali nel trovare la
soluzione più elegante, estetica e leggera. Vogliamo che ciò che produciamo non deluda le attese ma,
più di ogni altra cosa, voglamo che ci piaccia.
Mastichiamo tutti i linguaggi e i framework ma decidiamo di portare sulle nostre tavole quelli che ci convincono di più in termini di scalabilità ed efficienza: sapremo trovarne uno idoneo per ogni esigenza.











Scrivi il tuo commento